プログラムを日本語で記述するとソースコードの可読性を大幅に上げることができます。

予約語と記号以外は日本語で記述できる
現在のほとんどのプログラミング言語は下図のように予約語と記号以外を日本語で記述できます。
$ローマ字テーブル = 標準テーブルを読み込む();
っを置換($ローマ字テーブル);
んを置換($ローマ字テーブル);
function っを置換(&$ローマ字テーブル)
{
foreach($ローマ字テーブル as $キー => $要素) {
if($要素[0]=='っ')
unset($ローマ字テーブル[$キー]);
}
$ローマ字テーブル[';'] = ['っ'];
}
function んを置換(&$ローマ字テーブル)
{
$キーの配列 = array_keys($ローマ字テーブル,['ん']);
foreach($キーの配列 as $キー)
unset($ローマ字テーブル[$キー]);
$キーの配列 = array_keys($ローマ字テーブル);
foreach($キーの配列 as $キー) {
if(mb_substr($キー,0,1)=='q')
unset($ローマ字テーブル[$キー]);
}
$ローマ字テーブル['q'] = ['ん'];
}
メリット
プラグラムを日本語で書くメリットはその圧倒的な読みやすさです。
日本人の母語である日本語が英語よりわかりやすいのはもちろんですが、漢字が表意文字であることも大きいです。
表音文字の羅列である英語は(頭の中で)読んで音にしないと意味が取れません。
それに対し、表意文字である漢字は(頭の中で)読まなくても文字を見るだけで理解できます。
プログラムのソースコードは熟読よりも流し読みの方が遥かに多いため、この違いは大きいです。
デメリット
にもかかわらず日本語で書かれたプログラムはほとんど見かけません。
それは以下のようなデメリットがあるからだと思われます。
- 全角英数字がエラーになる
- プログラムが日本語で書けることを知らない
- コーディング規約で日本語禁止
全角英数字がエラーになる
日本のIT業界は「全角英数字」なる負の遺産を引きずっています。
例えば同じ「A」でも通常はA、全角がAです。
区別できるでしょうか?
どちらも同じAという文字ですが、ほぼ全てのプログラミング言語が全角のAを文字として理解できません。
つまり、プログラムの予約語(ifとかforとか)や記号(+とか)が全角で書かれるとプログラム言語は何かおかしな文字があるとみなしエラーにします。
プログラム言語ではインデントなどで多用されるスペース(空白)も同じです。
実は日本語文章では「全角スペース」なる全く意味不明なものが多用されています。
この全角スペースがプログラムのインデントなどに混入するとプログラム言語はおかしな文字があるとみなし、人間が目視してもただの空白にしか見えない場所をエラーにしてしまいます。
しかし、後述のように「Google日本語入力」や「UDEV Gothic」を使うとこの全角英数字の問題を回避できます。
プログラムが日本語で書けることを知らない
昔のプログラミング言語は日本語(正確にはUNICODE形式のソースコード)を扱えませんでした。
さらに昔はGoogle日本語入力(後述)もありませんでした。
その時代からプログラムを始めた人には日本語ではプログラムできないと思いこんでいる人が多いかもしれません。
コーディング規約で日本語禁止
コーディング規約とはソースコードの書き方のルールです。
よくあるのがグローバルで開発する会社でコメントも含めて英語以外は使用禁止というものです。
そのような会社では当然、プログラムの仕様書も英語のみです(仕様書が日本語では仕様書を読めない人がプログラムを書くことになってしまいます)。
ただ、プログラムを日本語で書けなかった時代に作られた日本語禁止の規約が惰性で使われている場合もあります。
古いコーディング規約は見直すと生産性が上がるかもしれません。
日本語IMEの設定
プログラムを日本語で書くには当然、日本語IME(日本語を入力するためのソフトウェア)を使います。
しかし、日本語IMEは全角英数字も入力できてしまうためソースコードにそれが混入してしまい、前述のようにエラーになってしまうことがよくあります。
それを避けるためには日本語IMEが全角英数字を出力しなければいいのですが、WindowsやMacの標準IMEではできません。
ChromeOSに搭載されているGoogle日本語入力でもできません。

WindowsかMac用のGoogle日本語入力なら以下のように全角英数字を出力しない設定が可能です。
「Google日本語入力プロパティ」画面の「一般」タブで「スペースの入力」と「テンキーからの入力」を「半角」にします。
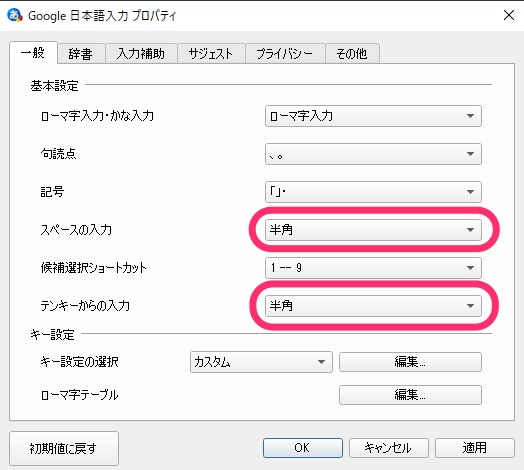
「入力補助」タブで「自動英数変換」をON、「シフトキーでの入力切替」を「英数字」にします。
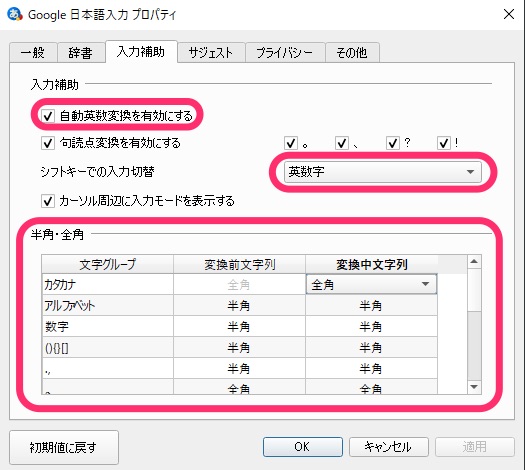
「半角・全角」は以下のように設定します。
| 文字グループ | 変換前文字列 変換中文字列 |
|---|---|
| カタカナ | 全角 |
| アルファベット | 半角 |
| 数字 | |
| (){}[] | |
| ., | |
| 。、 | 全角 |
| ・「」 | |
| “‘ | 半角 |
| :; | |
| #%&@$^|` | |
| ~ | |
| <>=+-/* | |
| ?! |
この設定で以下の記号以外ならIMEをONにしたまま入力できます。
- [
- ]
- /
- ,
- .
日本語配列キーボードが有利
プログラミングでは記号を多用するためか日本語配列より記号入力のしやすい英語キーボードを好むプログラマーが多いかと思います。
しかし、プログラムを日本語で書くなら英語キーボードより以下の点で日本語キーボードが有利です。
- IME操作専用キーがある
- 変換確定のためのリターンキーが押しやすい
日本語配列にはいろいろ問題はあるものの、わざわざ日本語専用の配列を作っただけのことはあります。
UDEV Gothic
UDEV Gothicとは日本語プログラミングのためのフォントです。
前述の全角スペースのエラーを「全角スペースの可視化」や複数文字で構成される演算子の合字などプラグラマーのためのフォントです。
もちろん、VSCodeでも使えます。
MarkdownやHTMLにも有効
全角英数字が混入すると困るのはMarkdownやHTMLも同様です。
プログラムを日本語で書くための設定はそれらの記述にも有効です。
コメント