
PDFファイルに含まれている画像を取り出すにはどうしたらいいでしょうか。


自炊PDFからスキャンした画像を取り出したい
電子書籍の自炊を初めた当初はPDF形式で自炊していました。
PDFであればパソコンでもタブレットでも読めて便利だろうと思ったからです。
しかし、実際にはPerfect Viewerなどの自炊本ビューワーではPDFよりCBZのほうが扱いやすいことに気がつきました(一応、Perfect ViewerではプラグインでPDFも扱えますが)。

そこでPDFファイルから画像ファイルを取り出そうとしたわけです。

PDFから画像へ「変換」ではダメ
PDFファイルの「ページ」を画像に「変換」する方法はいろいろ存在します。
しかし、PDFの各ページを画像に「変換」してみると、変換された画像ファイルの解像度がスキャン時に設定した解像度と違っていることに気が付きました。
自炊したPDFの各ページはスキャナーが出力した画像そのままのはずです。
それなのになぜ、スキャナーが出力した画像と違うものになるのでしょうか???
PDFから変換された画像は劣化している
よくよく考えてみるとPDFから画像への「変換」では自炊PDFのような全ページが画像で構成されるPDFだけでなく、文字で構成されたPDFからも画像ファイルが得られます。
なぜかというとPDF中の文字を「一定の解像度で描画」した結果を画像にしているから……
たとえ自炊PDFのような画像だけで構成されたPDFであっても「一定の解像度で描画」した結果が画像ファイルになります。
ページ内の画像を一定の解像度で描画するためには少なくとも拡大縮小の処理は必須なうえ、色の調整等もされているかもしれません。
これではページ内の画像がそのまま得られるわけはなく、変換された画像は描画の過程で劣化しています。
せっかく苦労して自炊した本をこんな方法で劣化させてはダメです。
PDFから画像を「抽出」する
必要なのは自炊PDFを画像に「変換」することではなく、自炊PDFの各ページに格納されている画像を「抽出」することでした。
PDFの開発元であるAdobe純正のAcrobat Proを使えばPDFから画像を抽出できます。
ただ、Acrobat ProはCreative Cloudと呼ばれるサブスリクプション(継続して利用料金を支払うアプリ)です。

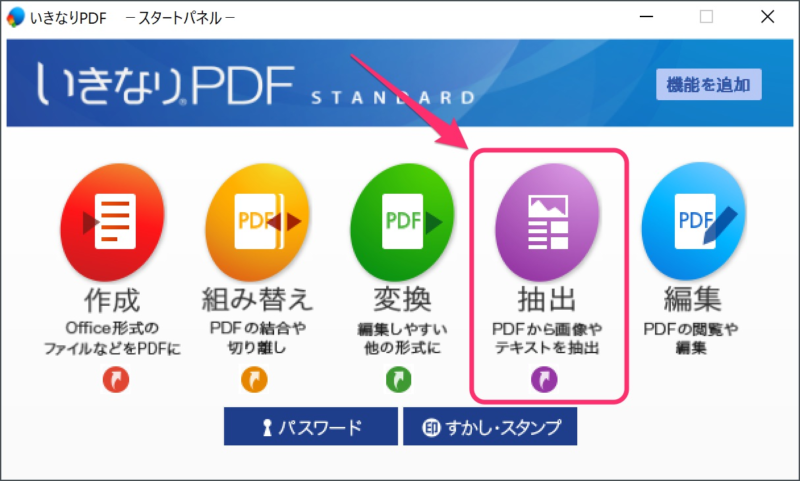
サブスクリプションに抵抗があれば、「いきなりPDF」の抽出機能を使うとPDFファイル内の画像データを一括で抽出できます。

いきなりPDFを起動し、スタートパネルの「抽出」をクリックします。
「対象ファイル選択」画面で画像を抽出するPDFファイルを選択します。
「処理中」画面に画像抽出の進捗状況が表示されます。
画像ファイルが保存されたフォルダが開きます。
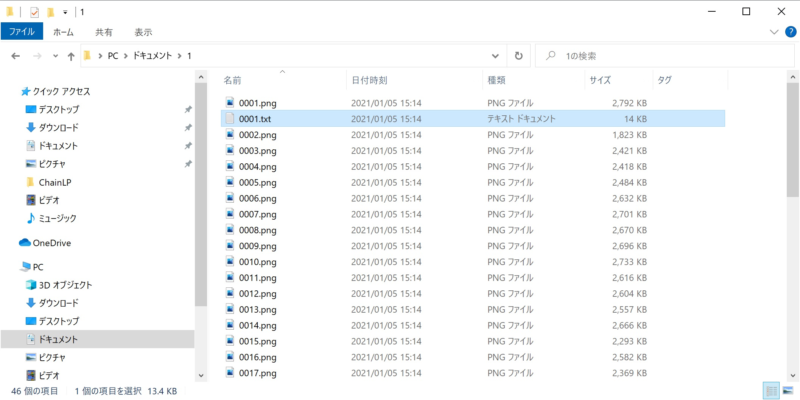
拡張子TXTのファイルはPDF中のテキストデータです。
拡張子PNGが抽出された画像ファイルです。
コメント